LeetCode - Flatten a Multilevel Doubly Linked List - Day5 (1/5/2020)
Flatten a Multilevel Doubly Linked List
Question
You are given a doubly linked list which in addition to the next and previous pointers, it could have a child pointer, which may or may not point to a separate doubly linked list. These child lists may have one or more children of their own, and so on, to produce a multilevel data structure, as shown in the example below.
Flatten the list so that all the nodes appear in a single-level, doubly linked list. You are given the head of the first level of the list.
Example 1:
Input: head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12] Output: [1,2,3,7,8,11,12,9,10,4,5,6] Explanation: The multilevel linked list in the input is as follows:
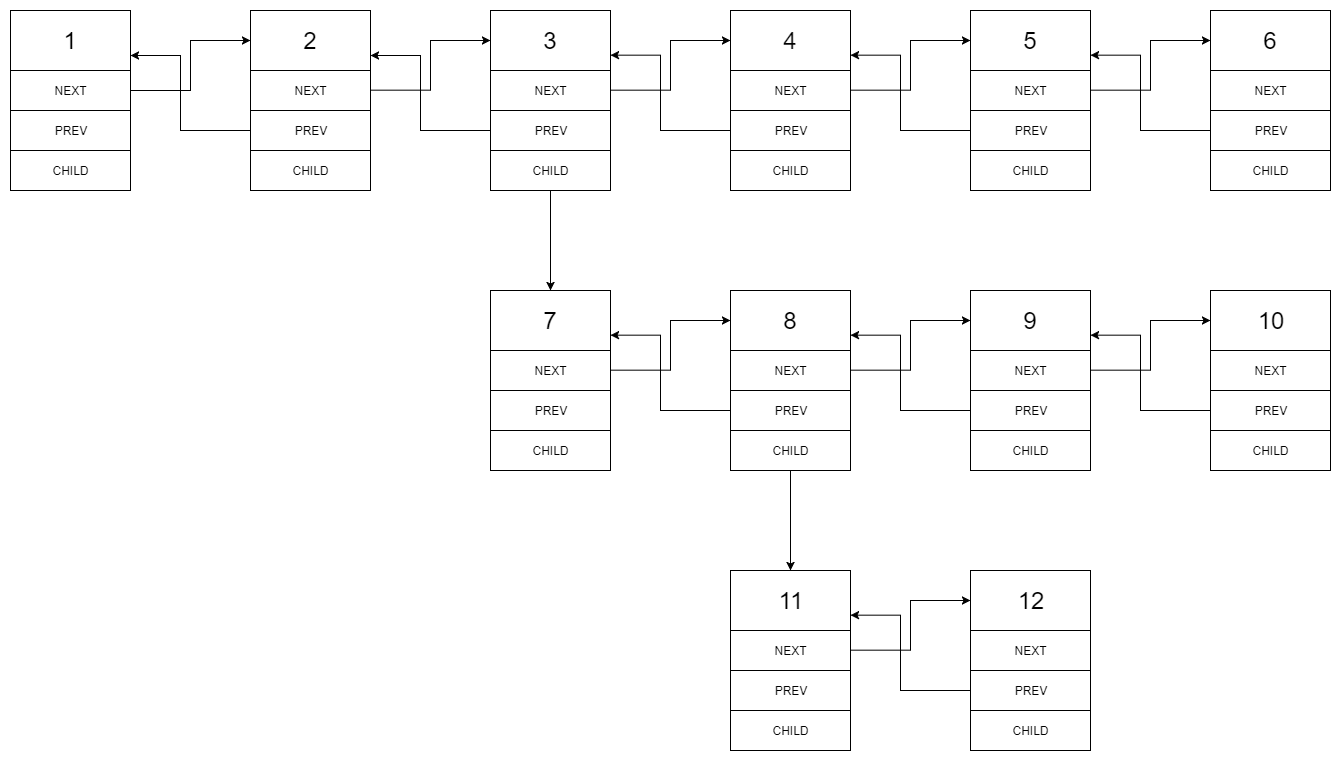
Example 2:
Input: head = [1,2,null,3] Output: [1,3,2] Explanation: The input multilevel linked list is as follows: 1---2---NULL | 3---NULL
Example 3:
Input: head = [] Output: []
Constraints:
Number of Nodes will not exceed 1000.
1 <= Node.val <= 105
Solution
To be honest, I couldn't come up with any idea to solve this problem. Also, I wondered which scenario that one would use such an awkward data structure.
The author said one fo the scenarios could be a simplified version of git branching. That makes sense. I wanna see how git branching system is implemented.
Maybe gitlab is good since it's OSS?
Approach 1: DFS by Recursion
Anyways, let's start solving this question. According to the solution, we can interpret this data structure as a binary tree string below.

Also, the process of flattening can be pre-order DFS (Depth-First Search) traversal.
So, let's think the chiled pointer as the left pointer in a binary tree and similarly, the next pointer as the right pointer in a binary tree.
Here it goes with the recursive DFS algorithm:
First of all, we define our recursive function as
flattenDFSwhich takes two pointers as input and returns the pointer of tail in the flattened list. Thecurrpointer leads to the sub-list that we would like to flatten, and theprevpointer points to the element that should precede thecurrelement.Within the recursion function, we first establish the double links between the
prevandcurrnodes, as in the pre-order DFS we take care fo the current state first before looking into the children.Further in the function, we then go ahead to flatten the left subtree with the call of
flattenDFS, which returns thetailelement to the flattened sublist. Then with thetailelement of the previous sublist, we then further flatten the right subtree, with the call offalttenDFS.There are two additional important details that we should attend to, in order to obtain the correct result:
We should make a copy of the curr.next pointer before the first recursive call of
flattenDFS), since the curr.next pointer might be altered within the function.After we flatten the sublist pointed by the curr.child pointer, we should remove the child pointer since it is no longer needed in the final result.
Last by not the least, one would notice in the following implementation that we create a pseudoHead variable in the function. This is not absolutely necessary, but it would help us to make the solution more concise and elegant by reducing the null pointer checks (e.g. if prev == null). And with less branching tests, it certainly helps with the performance as well. Sometimes people might call it sentinel node. As one might have seen before, this is a useful trick that one could apply to many problems related with linked lists (e.g. LRU cache).
public Node flatten(Node head) { if (head == null) { return head; } Node pseudoHead = new Node(0, null, head, null); flattenDFS(pseudoHead, head); pseudoHead.next.prev = null; return pseudoHead.next; } public Node flattenDFS(Node prev, Node curr) { if (curr == null) { return prev; } curr.prev = prev; prev.next = curr; Node tempNext = curr.next; Node tail = flattenDFS(curr, curr.child); curr.child = null; return flattenDFS(tail, tempNext); } public class Node { public int val; public Node prev; public Node next; public Node child; public Node() {} public Node(int _val,Node _prev,Node _next,Node _child) { val = _val; prev = _prev; next = _next; child = _child; } }
Approach 2
Use iteration.
public Node flatten(Node head) { if (head == null) return head; Node pseudoHead = new Node(0, null, head, null); Node curr, prev = pseudoHead; Deque<Node> stack = new ArrayDeque<>(); stack.push(head); while (!stack.isEmpty()) { curr = stack.pop(); prev.next = curr; curr.prev = prev; if (curr.next != null) stack.push(curr.next); if (curr.child != null) { stack.push(curr.child); // don't forget to remove all child pointers. curr.child = null; } prev = curr; } // detach the pseudo node from the result pseudoHead.next.prev = null; return pseudoHead.next; }